Evaluating and comparing
Because LLMs generally are part of broader agent systems, it is important to evaluate them. While model evaluation and prompt evaluation is essential to understanding optimizing individual components, it is essential to evaluate the higher-level agents and agent systems.
There is a lot of similarity of what to evaluate for models, so we primarily focus on tools and methods of how to evaluate
How to Evaluate¶
??? abstract "MLE-BENCH: EVALUATING MACHINE LEARNING AGENTS ON MACHINE LEARNING ENGINEERING
The authors share in their [paper](https://arxiv.org/pdf/2410.07095) at kaggle-competition environmet for agents surrounding ML challenges.
<img width="550" alt="image" src="https://github.com/user-attachments/assets/10909e0f-6787-4f6c-a95b-6b1d7210d02a">
<img width="592" alt="image" src="https://github.com/user-attachments/assets/ab8789d4-f9d3-4875-a777-1bc381e785cc">
Promptfoo: a tool for testing and evaluating LLM output quality
With promptfoo, you can:
Systematically test prompts, models, and RAGs with predefined test cases Evaluate quality and catch regressions by comparing LLM outputs side-by-side Speed up evaluations with caching and concurrency Score outputs automatically by defining test cases Use as a CLI, library, or in CI/CD Use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API
 DeepEval provides a Pythonic way to run offline evaluations on your LLM pipelines
DeepEval provides a Pythonic way to run offline evaluations on your LLM pipelines
"... so you can launch comfortably into production. The guiding philosophy is a "Pytest for LLM" that aims to make productionizing and evaluating LLMs as easy as ensuring all tests pass."
 It integrates with Llama index here
It integrates with Llama index here
??? note "API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs
There is a growing need for Large Language Models (LLMs) to effectively use tools and external Application Programming Interfaces (APIs) to plan and complete tasks. As such, there is tremendous interest in methods that can acquire sufficient quantities of train and test data that involve calls to tools / APIs. Two lines of research have emerged as the predominant strategies for addressing this challenge. The first has focused on synthetic data generation techniques, while the second has involved curating task-adjacent datasets which can be transformed into API / Tool-based tasks. In this paper, we focus on the task of identifying, curating, and transforming existing datasets and, in turn, introduce API-BLEND, a large corpora for training and systematic testing of tool-augmented LLMs. The datasets mimic real-world scenarios involving API-tasks such as API / tool detection, slot filling, and sequencing of the detected APIs. We demonstrate the utility of the API-BLEND dataset for both training and benchmarking purposes.
 Arthur.ai Bench Bench is a tool for evaluating LLMs for production use cases.
Arthur.ai Bench Bench is a tool for evaluating LLMs for production use cases.
Auto Evaluator (Langchain) with  github to evaluate appropriate components of chains to enable best performance
github to evaluate appropriate components of chains to enable best performance
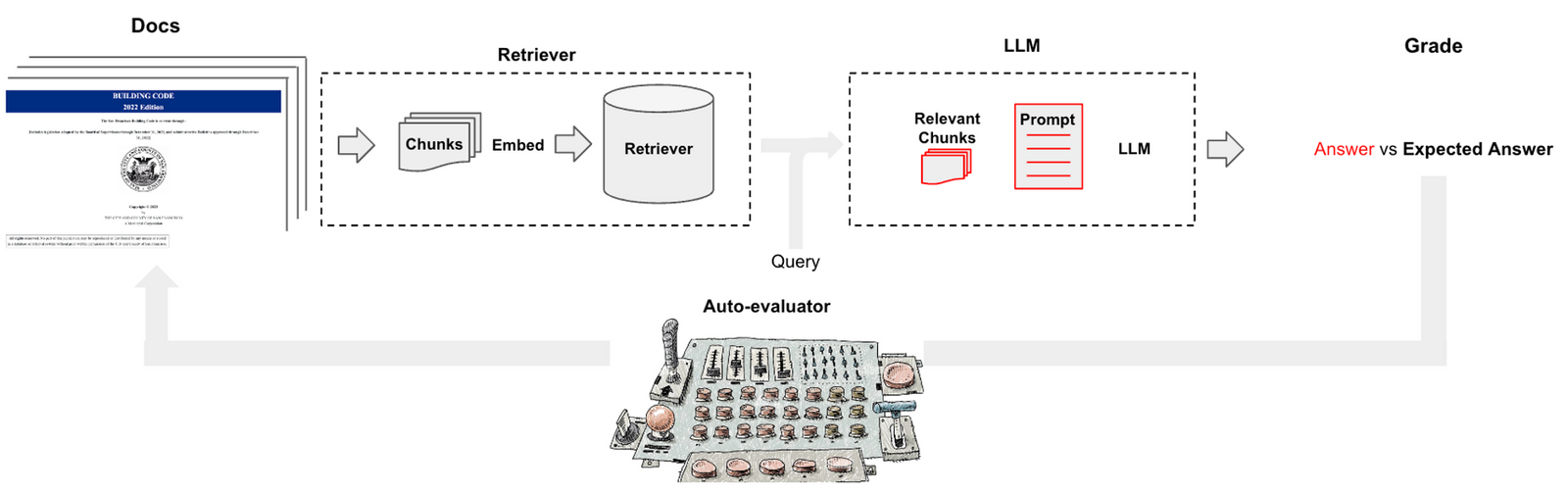
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Where in their paper they demonstrate an emulation container to evaluate the safety of an Agent.
 AgentBench: Evaluating LLMs as Agents
AgentBench: Evaluating LLMs as Agents
A comprehensive 8-environment evaluation for different agents from different models.
Paper
 JudgeLM: Fine-tuned Large Language Models are Scalable Judges trains LLMs to judge the outputs of LLMs based on reference examples and achieves greater coherence than human rating
JudgeLM: Fine-tuned Large Language Models are Scalable Judges trains LLMs to judge the outputs of LLMs based on reference examples and achieves greater coherence than human rating
Also provides a great example GUI and interface using GradIO
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Abstract: Large Language Models (LLMs) have unlocked new capabilities and applications; however, evaluating the alignment with human preferences still poses significant challenges. To address this issue, we introduce Chatbot Arena, an open platform for evaluating LLMs based on human preferences. Our methodology employs a pairwise comparison approach and leverages input from a diverse user base through crowdsourcing. The platform has been operational for several months, amassing over 240K votes. This paper describes the platform, analyzes the data we have collected so far, and explains the tried-and-true statistical methods we are using for efficient and accurate evaluation and ranking of models. We confirm that the crowdsourced questions are sufficiently diverse and discriminating and that the crowdsourced human votes are in good agreement with those of expert raters. These analyses collectively establish a robust foundation for the credibility of Chatbot Arena. Because of its unique value and openness, Chatbot Arena has emerged as one of the most referenced LLM leaderboards, widely cited by leading LLM developers and companies. Paper