Index
Models must yield results that are sufficiently good for downstream users. This is quite often the accuracy, an evaluation and comparison metric. Efficiency another is a crucial aspect of AI model development. The ability to generate high-performing content quickly can significantly impact the overall performance of your AI model. Although there isn't a universally accepted solution, several methods can help optimize your model for better efficiency without compromising quality.
Most successful models employ a combination of approaches to reduce model sizes. This document provides an understanding of these methods and how they can be applied to optimize your AI model.
Model metric optimizations¶
MANAGEN(Please describe model optimization methods and what is mentioned below)
- Data (quality and volume)
- Hyper parameters: Batch size is important. Use gradient accumulation if possible.
- Model size
- Model structure (BERT vs last-token prediction)
Model Performance Optimization¶
The following are some of the commonly used methods for optimizing AI models:
- Pruning
- Quantization
- Knowledge Distillation
- Low-rank and sparsity approximations
- Mixture of Experts
- Neural Architecture Search (NAS)
- Hardware enabled optimization
- Compression
- Caching
Pruning¶
Pruning is a technique that eliminates weights that do not consistently produce highly impactful outputs.
======
The Unreasonable Ineffectiveness of the Deeper Layers
Using a pruning strategy informed by similarity, the authors demonstrate that eliminating up to 40% of for Llama models, does not yield significant reduction in accuracy.  outperforms existing pruning methods in terms of scalability and performance tradeoffs, and it does so by leveraging advances from several fields, including high-dimensional statistics, combinatorial optimization, and neural network pruning."
Related to pruning is the use of smaller models that are initialized based on larger ones
 Weight Selection
Weight Selection
A nice way to initialize smaller models from bigger ones
Paper
 Transformer Compression with SliceGPT
Transformer Compression with SliceGPT
Developments In their paper the authors reveal that a manner of replacing matrices with dense smaller dense matrices reducing the embedding dimensions. This can eliminate up to 25% of parameters (and embeddings) for LLama-2, and maintain 99% zero shot task performance across multiple models.
Quantization¶
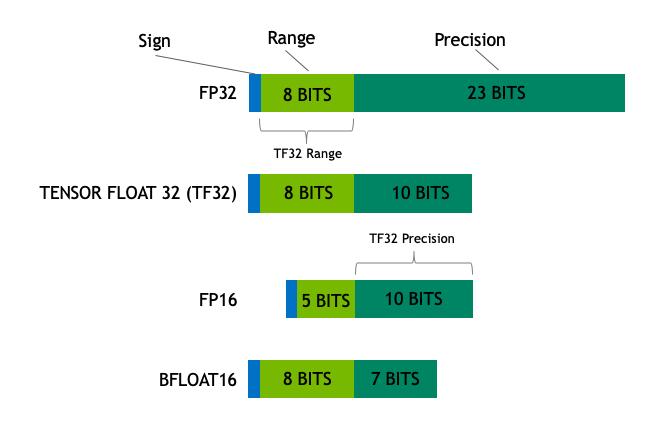
Precision details the manner in which binary bits represent numbers in a computer. Generally, the greater the number of bits, the broader the variety of numbers that can be represented.
Broken down into the exponent and fraction, as the different values can have specific implications for the training of models. Quite generally, bfloat16 (developed by Google Brain) offers an effective balance of size and dynamic expressibility for LLMs, and is a well-used number format.
To have improved performance, the models may be reduced, however, to using fewer bits. Standard fp16 may sometimes reduced to int8, and even binary representations.
What is Precision?
======
When to quantize: During or after training?¶
There are general times when quantization may be performed. During training, post-training. Here are the benefit chart for each method each kind:
MANAGEN: (Table with this the characteristic chart of the different methods to help individuals know specific challenges and benefits)
Examples¶
 SmoothQuant: Accurate and Efficient Post-trainign Quantizationf or LLMs
SmoothQuant: Accurate and Efficient Post-trainign Quantizationf or LLMs
Using some post-training smoothing, they shift the weights in such a way that they are easier to quantize.
Paper
HF bitsandbytes and code From Github
 PB-LLM: Partially Binarized Large Language Models to compress identified model weights into a single bit, while allowing others to only be partially compressed.
PB-LLM: Partially Binarized Large Language Models to compress identified model weights into a single bit, while allowing others to only be partially compressed.
GPTVQ: The Blessing of Dimensionality for LLM Quantization
The authors "show that the size versus accuracy trade-off of neural network quantization can be significantly improved by increasing the quantization dimensionality. We propose the GPTVQ method, a new fast method for post-training vector quantization (VQ) that scales well to Large Language Models (LLMs). Our method interleaves quantization of one or more columns with updates to the remaining unquantized weights, using information from the Hessian of the per-layer output reconstruction MSE. Quantization codebooks are initialized using an efficient data-aware version of the EM algorithm. The codebooks are then updated, and further compressed by using integer quantization and SVD-based compression. GPTVQ establishes a new state-of-the art in the size vs accuracy trade-offs on a wide range of LLMs such as Llama-v2 and Mistral. Furthermore, our method is efficient: on a single H100 it takes between 3 and 11 hours to process a Llamav2-70B model, depending on quantization setting. Lastly, with on-device timings for VQ decompression on a mobile CPU we show that VQ leads to improved latency compared to using a 4-bit integer format."
Knowledge Distillation¶
Train a new smaller model using the output of bigger models. (TODO)
Fusion approaches¶
Knowledge Distillation and Compression Demo.ipynb
??? abstract " SqueezeLLM They are able to have 2x fold in model size for equivalent performance in perplexity. They use 'Dense and SParce Quantization'
SqueezeLLM
Low rank and sparsity approximations¶
TODO
GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Developments "For the first time, we show that the Llama 7B LLM can be trained on a single consumer-grade GPU (RTX 4090) with only 24GB memory. This represents more than 82.5% reduction in memory for storing optimizer states during training.
Training LLMs from scratch currently requires huge computational resources with large memory GPUs. While there has been significant progress in reducing memory requirements during fine-tuning (e.g., LORA), they do not apply for pre-training LLMs. We design methods that overcome this obstacle and provide significant memory reduction throughout training LLMs.
Training LLMs often requires the use of preconditioned optimization algorithms such as Adam to achieve rapid convergence. These algorithms accumulate extensive gradient statistics, proportional to the model's parameter size, making the storage of these optimizer states the primary memory constraint during training. Instead of focusing just on engineering and system efforts to reduce memory consumption, we went back to fundamentals.
We looked at the slow-changing low-rank structure of the gradient matrix during training. We introduce a novel approach that leverages the low-rank nature of gradients via Gradient Low-Rank Projection (GaLore). So instead of expressing the weight matrix as low rank, which leads to a big performance degradation during pretraining, we instead express the gradient weight matrix as low rank without performance degradation, while significantly reducing memory requirements."
Model Merging¶
 🐟 Evolutionary Optimization of Model Merging Recipes
🐟 Evolutionary Optimization of Model Merging Recipes
Developments: The authors demosntrate a "a new paradigm for automated model composition, paving the way for exploring alternative, efficient approaches to foundation model development" by merging models.
Combination Approaches¶
 QLoRA: Efficient Finetuning of Quantized LLms uses Quantization and Low-Rank Adapters to enable SoTA models with even smaller models
QLoRA: Efficient Finetuning of Quantized LLms uses Quantization and Low-Rank Adapters to enable SoTA models with even smaller models
Hardware enabled optimization¶
LLM in a flash: Efficient Large Language Model Inference with Limited Memory
Large language models (LLMs) are central to modern natural language processing, delivering exceptional performance in various tasks. However, their intensive computational and memory requirements present challenges, especially for devices with limited DRAM capacity. This paper tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters on flash memory but bringing them on demand to DRAM. Our method involves constructing an inference cost model that harmonizes with the flash memory behavior, guiding us to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks. Within this flash memory-informed framework, we introduce two principal techniques. First, “windowing” strategically reduces data transfer by reusing previously activated neurons, and second, “row-column bundling”, tailored to the sequential data access strengths of flash memory, increases the size of data chunks read from flash memory. These methods collectively enable running models up to twice the size of the available DRAM, with a 4-5x and 20-25x increase in inference speed compared to naive loading approaches in CPU and GPU, respectively. Our integration of sparsity awareness, context-adaptive loading, and a hardware-oriented design paves the way for effective inference of LLMs on devices with limited memory
Compression¶
Learning to Compress Prompts with Gist Tokens. Can enable 26x compression and 40% FLOP reduction and improvements by training 'gist tokens' to summarize information.
Caching¶
KV-Cache Optimization
MODEL TELLS YOU WHAT TO DISCARD:ADAPTIVE KV CACHE COMPRESSION FOR LLMS
This method performs dynamic ablation of KV pairs minimizing the number of computes that need to happen. They just remove K-V cach
Tooling¶
by provides a lightweight wrapper around CUDA custom functions, in particular 8-bit optimizers, matrix multiplication (LLM.int8()) Bitsandbytes by provides a lightweight wrapper around CUDA custom functions, in particular 8-bit optimizers, matrix multiplication (LLM.int8()), and quantization functions.